Python represents each “Data Type” by a class; So each data is a sample or object of a specific class. Although the programmer can also define the class of his choice, in this lesson we want to talk about that part of the data types or types of objects that are provided to the Python interpreter in a ready-made (Built-in) way.
This lesson will only look at “numeric object types” and “string types” in Python, and the remaining types will be explored in the next lesson. Although efforts have been made to provide complete details, in some areas, reading Python official documents can provide you with more complete information. Many Python-ready functions will be used, which may be more detailed than what is described in this lesson; For this reason, a link to their definition is also provided in the Python documentation. The important point in studying this lesson is to examine the sample code, which sometimes it will be impossible to understand the explanation given without accuracy in this sample code.
✔ Level: Introductory
Headlines
Lesson 07: Data Types or Objects in Python: Part 1
- True
- Floating point
- mixed
- December
- Kasr
- boolean
- field
Numerical types
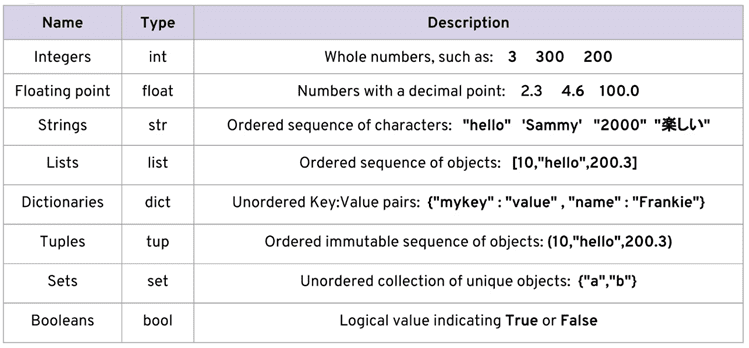
In Python, there are a bunch of object types created to work with numerical data; For this reason, they are known as “Numeric Types”. These types of objects are:
- True (Integer)
- Floating-Point
- Complex
- Decimal
- Fraction
- Boolean
In the following, we will examine each one.
True
These types of objects include all positive and negative numbers without a “decimal point”; Such as: 1234, 26- and …
Providing integer type is one of the differences in 2x and 3x versions.
In 2x versions, integers are expressed in two types: int (with size limit) and long (without size limit):
>>> a = 3 # Python 2.x >>> type(a) <type 'int'> >>> b = 3L >>> type(b) <type 'long'>
In such a way that if an integer ends with the letter L (large el) or l (small el); It will be considered as a long type. Note, however, if overflow occurs in the int type; There will be no error and Python will automatically convert the int object to a long object.
The maximum and minimum values of an object of type int can be obtained using sys.maxint and sys.maxint-1, respectively. You can see these values in a sample computer with a 64-bit architecture below:
>>> import sys # Python 2.x >>> sys.maxint 9223372036854775807 >>> type(_) # _ is result of the last executed statement => 9223372036854775807 <type 'int'> >>> - sys.maxint - 1 -9223372036854775808 >>> type(sys.maxint + 1) <type 'long'>
In 3x versions, integers are presented only in the form of an int type (without size limit) and it should be noted that the use of the letter L (or l) at the end of integers is not allowed:
>>> a = 3 # Python 3.x >>> type(a) <class 'int'> >>> b = 3L File "<stdin>", line 1 b = 3L ^ SyntaxError: invalid syntax >>>
In these versions, sys.maxint has been removed, but you can use sys.maxsize instead, the value of which is too low in the computer sample:
>>> import sys # Python 3.x >>> sys.maxsize 9223372036854775807 >>> type(_) <class 'int'> >>> type(sys.maxsize + 1) <class 'int'>
Attention
The unlimited size of numbers means that the size of these objects is limited only by the amount of free memory (Memory) and they can grow in calculations as much as memory is available.

In both branches of Python; Integers can be based on addition; Binary, Octal and Hexadecimal were also considered. As follows:
- Base numbers two must start with a 0b or 0B (zero and uppercase or lowercase letters); Such as: 0b11 which is equal to the number 3 in base ten:
>>> a = 0b11 >>> type(a) <class 'int'> >>> a 3
- Base numbers eight must start with a 0o or 0O (zero and uppercase or lowercase letters); Such as: 0o14 which is equal to 12 in base ten:
>>> a = 0o14 >>> type(a) <class 'int'> >>> a 12
Also in 2x versions, you can use only one zero instead of 0o or 0O to specify a number in this base:
>>> 0o14 # Python 3.x and Python 2.x 12 >>> 014 # Python 2.x 12
- Base numbers sixteen must start with a 0x or 0X (zero and uppercase or lowercase); Such as: 0xA5 which is equal to 165 in base ten:
>>> a = 0xA5 >>> type(a) <class 'int'> >>> a 165 >>> print(a) 165
As can be seen in the sample code above; The correct object type does not differ on different bases (int), and in Python only a different syntax is used to specify them. Also in addition to entering these objects in interactive mode; The print function (or command) also converts these objects to base ten and then prints them.
To convert an integer in base ten to any of these bases, you can use the ready-made functions bin () [Python documents] to convert to base two, oct () [Python documents] to convert to base eight, and hex () (Python documents) Use to convert to base sixteen. Just note that the output of each of these functions is returned as a string object, not a numeric one:
>>> a = 3 >>> b = bin(a) >>> b '0b11' >>> type(b) <class 'str'> >>> a = 12 >>> b = oct(a) >>> b '0o14' >>> type(b) <class 'str'> >>> a = 165 >>> b = hex(a) >>> b '0xa5' >>> type(b) <class 'str'>
And to return the integer base to base ten, you can use the int (Python documentation) class (). Sample arguments of this class are int (str, base); the first argument: str must be a “numeric string”, ie an integer (in any base) inside the quotation symbols (quote) that the second argument, its base (Base) Finally, this class returns an int object corresponding to the first argument but at base ten:
>>> a = 165 >>> type(a) <class 'int'> >>> b = hex(a) # Converted to hexadecimal >>> b '0xa5' >>> type(b) <class 'str'> >>> int(b, 16) # str='0xa5' base=16 165 >>> type(int(b, 16)) <class 'int'>
Note that numbers can be sent to this class without the base letter (0x 0o 0b). This class can also be used to convert numeric string types in base ten to integers. The default value of the base argument is 10; Therefore, when sending numbers in this base, there is no need to mention base 10:
>>> int("A5", 16) # 0xA5
165
>>> a = "56" >>> int(a, 10) 56 >>> int(a) 56
>>> int() 0
() int returns an object of zero type without argument without an argument.
Attention
“Numerical string” means a string that can be evaluated as a number. Such as: “25”, “0x2F” and … which obviously put strings like “0w55” and … – which in no way can be numerically evaluated in Python – in the int () argument causes an error Turns.

We are familiar with the difference between the method of presenting the type of integers between the 2x and 3x versions of Python. Just note that in 2x versions of Python; The int () class [Python Documents] returns an object of type int and is available to create objects of the long class of another similar class called long () (Python Documents):
>>> a = 25 # Python 2.x >>> int(a) 25 >>> long(a) 25L
In both branches of Python; Numbers in the base ten can also be passed to the int () (long) function with a numeric type – not as a numeric string.
To get the size or amount of memory taken by an object per byte, we can use the getsizeof () function inside the sys module – the output of this function for two arbitrary objects in a 64-bit computer instance. Face down:
>>> import sys # Python 3.x >>> a = 1 >>> sys.getsizeof(a) 28 >>> sys.getsizeof(10**100) 72
>>> import sys # Python 2.x >>> a = 1 >>> sys.getsizeof(a) 24 >>> sys.getsizeof(10**100) 72
Floating point
All positive and negative numbers that contain a “decimal point” in Python are represented as float objects (equivalent to double in C); Such as: 3.1415, .5 (equal to 5.0) and …
>>> a = 3.1415 >>> type(a) <class 'float'> >>> import sys >>> sys.getsizeof(a) 24
Details of this type can be viewed using sys.float_info [Python Documents]:
>>> import sys >>> sys.float_info sys.float_info(max=1.7976931348623157e+308, max_exp=1024, max_10_exp=308, min=2.2250738585072014e-308, min_exp=-1021, min_10_exp=-307, dig=15, mant_dig=53, epsilon=2.220446049250313e-16, radix=2, rounds=1)
The “Scientific Notation” method is sometimes used to represent numbers; In Python, the letter E or e, which is equivalent to “multiplied by 10 to the power”, can also be used for this purpose.
For example, the expression 105*4 is expressed as 4E5 or 4e5. Python also presents these types of numbers in the form of floating point numbers (float objects):
>>> 3e2 300.0 >>> type(3e2) <class 'float'> >>> 3e-2 0.03 >>> 3e+2 300.0
The float () class can be used to convert numbers or numeric strings to a floating point object:
>>> a = 920
>>> type(a)
<class 'int'>
>>> float(a)
920.0
>>> type(float(a))
<class 'float'>
>>> float("920")
920.0
>>> float("3e+2")
300.0
>>> float() 0.0
The float () argument without argument returns a floating point zero object.
If a floating point number is included in the int () class argument; Only the integer part of the number is returned:
>>> a = 2.31 >>> type(a) <class 'float'> >>> int(a) 2 >>> type(int(a)) <class 'int'> >>> int(3.9) 3
Using the float () class, we can create objects with positive and negative values of “infinity” equal to: inf or infinity and “not a number” equal to: NaN – how to spell the letters of these words differently It does not cause:
>>> a = float('infinity')
>>> a = float('inf')
>>> a
inf
>>> b = float('-infinity')
>>> b = float('-inf')
>>> b
-inf
>>> c = float('NaN')
>>> c
nan
>>> a = float('inf')
>>> 5 / a
0.0
>>> a / a
nan
>>> a = float('inf')
>>> b = float('inf')
>>> a == b
True
>>> a = float('nan')
>>> b = float('nan')
>>> a == b
False
No two NaN objects are equal.
To check if the value of an object is “infinite” or “undefined”; We can use the isinf (Python documents) and isnan () functions in the math module, respectively:
>>> a = float('inf')
>>> b = float('nan')
>>> import math
>>> math.isinf(a)
True
>>> math.isnan(b)
True
mixed
As we know, Complex Numbers consist of a real part and an imaginary part. In Python, these numbers have a pattern equal to RealPart + ImaginaryPart j, where the letter j indicates an “imaginary unit”. These numbers in Python are represented by objects of complex type:
>>> a = 3 + 4j >>> type(a) <class 'complex'> >>> import sys >>> sys.getsizeof(a) 32
The complex (Python documents) class can be used to create a complex object. This class has a similar pattern (real, imag; the sample arguments real and imag represent numbers that are supposed to exist in the real and imaginary parts of the complex number, respectively. If any of the arguments are not sent, the default is zero in Will be considered:
>>> a = 3 >>> b = 4 >>> type(a) <class 'int'> >>> type(b) <class 'int'> >>> complex(a, b) (3+4j) >>> type(complex(a, b)) <class 'complex'>
>>> complex(3, 4) (3+4j) >>> complex(3) (3+0j) >>> complex(0, 4) 4j >>> complex(4j) 4j
>>> a = 3 + 4j >>> a (3+4j) >>> a = 3.2 + 4j >>> a (3.2+4j) >>> a = 3.0 + 4j >>> a (3+4j) >>> a = 3.0 + 4.0j >>> a (3+4j)
Also, using the two attributes real and imag, the real and imaginary parts of each complex object can be obtained. Note that regardless of the type of numbers involved in forming a complex type; The parts of the complex number are divided into floating point numbers:
>>> a = 3 + 4j >>> a.real 3.0 >>> a.imag 4.0
complex () also has the ability to receive a numeric string and convert it to a complex number. It should only be noted that there should be no empty space inside this string:
>>> a = "3+4j" >>> type(a) <class 'str'> >>> complex(a) (3+4j) >>> a = "3" >>> complex(a) (3+0j) >>> type(complex(a)) <class 'complex'>
>>> a = "3 + 4j" >>> complex(a) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: complex() arg is a malformed string >>>
Attention
It is not possible to put a numeric string (complex) or the complex number object itself in the arguments of the classes int (or (long)) and float () and it causes an error.
December
The basis of this type of design is for use in cases where the floating point type error is not forgivable [PEP 327] such as accounting program development. The Python interpreter uses Binary Floating-Point (IEEE 754) encoding to provide the floating point type to the computer. This encoding does not accurately represent the numbers in the base ten that the user wants – such as 0.1; For example, a number 0.1 equal to a number close to 0.100 trillion is included in computer calculations; Although this number is very close to 0.1, but it is not itself !. This may in some cases cause a logical error in the program:
>>> a = 0.1 + 0.1 + 0.1 >>> a == 0.3 False >>> a 0.30000000000000004
In the example code above, the user expects the second line statement to be evaluated with a True value, which does not happen.
In Python, the decimal type is available by creating an object of class Decimal inside the decimal module [Python documents]. Note the example code below:
>>> import decimal
>>> a = decimal.Decimal('0.1')
>>> b = decimal.Decimal('0.3')
>>> b == a + a + a
True
>>> type(a)
<class 'decimal.Decimal'>
>>> a
Decimal('0.1')
>>> print(a)
0.1
>>> import sys
>>> sys.getsizeof(a)
104
There are several ways to create a decimal object:
1 2 3 4 5 6 |
a = decimal.Decimal(23) # Creates Decimal("23")
b = decimal.Decimal("23.45") # Creates Decimal("23.45")
c = decimal.Decimal("2345e-2") # Creates Decimal("23.45")
d = decimal.Decimal((1,(2,3,4,5),-2)) # Creates Decimal("-23.45")
e = decimal.Decimal("infinity")
f = decimal.Decimal("NaN")
|
- Because the type of floating point is not accurate; Be sure to send these numbers as a string to Decimal (second row).
- Numbers can be sent as a Tuple object – a structure similar to: (…, Ο, Ο, Ο) – (fourth line). Remember the scientific symbol method; The target tuple should have a pattern-like structure (sign, digits, exponent) in which the sign indicates whether it is positive (by zero) or negative (by number one). exponent also represents the same power.
Precision and Rounding of Decimal Numbers can be controlled using a Context object; This object provides a set of configuration information to decimal objects that must be accessed using the getcontext (Python documentation) function inside the decimal module. The getcontext () function returns the current decimal object of the program. In multithreading, each thread has its own context object; So this function returns the Context object for the active thread:
>>> import decimal
>>> a = decimal.Decimal('3.45623')
>>> b = decimal.Decimal('0.12')
>>> a + b
Decimal('3.57623')
>>> print(a + b)
3.57623
>>> ctx = decimal.getcontext()
>>> type(ctx)
<class 'decimal.Context'>
>>> ctx.prec = 1
>>> a + b
Decimal('4')
>>> ctx.prec = 2
>>> a + b
Decimal('3.6')
>>> ctx.prec = 3
>>> a + b
Decimal('3.58')
As can be seen in the code example above, the accuracy of the decimal number calculations can be adjusted arbitrarily using the Context object attribute; The default value of this attribute is 28. Obviously, numbers need to be rounded in order to be in the smaller accuracy range of their length; To set the rounding operation in decimal numbers, the rounding attribute whose default value is “ROUND_HALF_EVEN” is also used:
>>> a = decimal.Decimal('2.0')
>>> b = decimal.Decimal('0.52')
>>> ctx.prec
28
>>> ctx.rounding
'ROUND_HALF_EVEN'
>>> print(a + b)
2.52
>>> ctx.prec = 2
>>> print(a + b)
2.5
>>> ctx.rounding = "ROUND_CEILING"
>>> print(a + b)
2.6
The rounding attribute must contain fixed values as follows:
- ROUND_CEILING – Rounding to Infinite Positive: That is, for positive numbers, out-of-range digits are omitted and the last remaining digit of one unit increases, for example, the number 2.52 is rounded to 2.6. For negative numbers, only numbers outside the range are omitted, for example, the number 2.19 is rounded to 2.1.
- ROUND_FLOOR – Rounding to Infinite Negative: That is, for negative numbers, the digits are out of range and the last remaining digit of one unit increases, for example, the number 2.52 is rounded to 2.6. For positive numbers, only out-of-range numbers are omitted, for example, the number 2.19 is rounded to 2.1.
- ROUND_DOWN – Round to zero: that is, for positive and negative numbers, only digits outside the range are removed, such as 2.58 to 2.5 and 2.58 to 2.5.
- ROUND_UP – Rounding away from zero: That is, for positive and negative numbers, out-of-range digits are removed and the last remaining digit of one unit increases, for example, the number 2.52 is rounded to 2.6 and the number 2.52 is rounded to 2.6.
- ROUND_HALF_DOWN – If the initial digit of the deleted section is greater than 5, it is rounded by ROUND_UP, otherwise it is rounded by ROUND_DOWN. For example, the number 2.58 is rounded to 2.6 and the number 2.55 to 2.5 is rounded, as well as the number 2.58 to 2.6 and the number 2.55 to 2.5.
- ROUND_HALF_UP – If the initial digit of the deleted section is greater than or equal to 5, it is rounded by ROUND_UP, otherwise it is rounded by ROUND_DOWN. For example, the number 2.55 is rounded to 2.6 and the number 2.51 to 2.5 is rounded – as well as the number 2.55 to 2.6 and the number 2.51 to -2.5.
- ROUND_HALF_EVEN – Same as ROUND_HALF_DOWN, but behaves differently when the initial digit of the deleted section is 5: In this case, if the last remaining digit is even, it is rounded by
- ROUND_DOWN, and if it is odd, it is rounded by ROUND_UP. For example, the numbers 2.68 rounds to 2.7, 2.65 to 2.6, and 2.75 to 2.8 – as well as the numbers 2.68 to 2.7, 2.65 to 2.6, and 2.75 to 2.8.
- ROUND_05UP – If the last remaining digit is 0 or 5 according to the ROUND_DOWN method; ROUND_UP, otherwise ROUND_DOWN. For example, the numbers 2.58 are rounded to 2.6 and 2.48 to 2.4 – as well as the numbers 2.58 to 2.6 and 2.48 to 2.4.
The decimal module or Python type contains many more details and features that you should read about in the Python documentation page.
Kasr
This type is provided to support rational numbers in Python and is made available by creating an object of the Fraction class inside the fractions module [Python Documents]:
>>> import fractions >>> a = 1 >>> b = 2 >>> f = fractions.Fraction(a, b) >>> f Fraction(1, 2) >>> print(f) 1/2 >>> type(f) <class 'fractions.Fraction'> >>> import sys >>> sys.getsizeof(f) 56
In addition to the above method, which directly specifies the face and denominator of the fraction – of the correct type; There are other ways to create a fractional object:
- From a floating point object – it is best to enter this type as a string:
>>> print(fractions.Fraction('0.5'))
1/2
>>> print(fractions.Fraction('1.1'))
11/10
>>> print(fractions.Fraction('1.5'))
3/2
>>> print(fractions.Fraction('2.0'))
2
>>> print(fractions.Fraction(0.5)) Fraction(1, 2) >>> print(fractions.Fraction(1.1)) 2476979795053773/2251799813685248 >>> 2476979795053773 / 2251799813685248 1.1 >>> print(fractions.Fraction(1.5)) 3/2
The limit_denominator () method can convert a floating point object into a fraction object by limiting the denominator to a maximum value:
>>> fractions.Fraction(1.1).limit_denominator() Fraction(11, 10)
>>> import math >>> math.pi 3.141592653589793 >>> pi = math.pi >>> fractions.Fraction(pi) Fraction(884279719003555, 281474976710656) >>> 884279719003555 / 281474976710656 3.141592653589793 >>> fractions.Fraction(pi).limit_denominator() Fraction(3126535, 995207) >>> 3126535 / 995207 3.1415926535886505 >>> fractions.Fraction(pi).limit_denominator(8) Fraction(22, 7) >>> 22 / 7 3.142857142857143 >>> fractions.Fraction(pi).limit_denominator(60) Fraction(179, 57) >>> 179 / 57 3.1403508771929824
- From a decimal object:
>>> print(fractions.Fraction(decimal.Decimal('1.1')))
11/10
- From a fraction fraction – the face and denominator of the fraction must be of the correct type:
>>> print(fractions.Fraction('3/14'))
3/14
- Subtract from another object:
>>> f1 = fractions.Fraction(1, 2) >>> f2 = fractions.Fraction(3, 5) >>> fractions.Fraction(f1) Fraction(1, 2) >>> fractions.Fraction(f1, f2) Fraction(5, 6)
Using the two attributes numerator and denominator, the form and denominator of the deductible object can be accessed, respectively:
>>> f = fractions.Fraction('1.5')
>>> f.numerator
3
>>> f.denominator
2
This type of object can easily be used in a variety of mathematical calculations; For example, look at the code snippet below:
>>> fractions.Fraction(1, 2) + fractions.Fraction(3, 4) Fraction(5, 4) >>> fractions.Fraction(5, 16) - fractions.Fraction(1, 4) Fraction(1, 16) >>> fractions.Fraction(3, 5) * fractions.Fraction(1, 2) Fraction(3, 10) >>> fractions.Fraction(3, 16) / fractions.Fraction(1, 8) Fraction(3, 2)
If a correct object is added to the fraction object, it is the result of a fraction object, but if a floating point object is added to the fraction object, it is the result of a floating point object:
>>> fractions.Fraction(5, 2) + 3 Fraction(11, 2) >>> fractions.Fraction(5, 2) + 3.0 5.5
B.M.M
Fractions module in addition to fraction type; It also contains the gcd () function [Python Documents]. This function returns the “largest common denominator” (GCD) of two numbers:
>>> import fractions >>> fractions.gcd(54, 24) 6
Boolean
The class used in Python to create a bool object is actually a child class of the integer class (int). This type of object can only have one of two values True (True) or False (False) that True is equal to integer 1 and False is equal to integer 0:
>>> a = True >>> a True >>> type(a) <class 'bool'> >>> import sys >>> sys.getsizeof(a) 28
>>> int(True) 1 >>> int(False) 0 >>> float(True) 1.0 >>> complex(True) (1+0j)
>>> True + 1 2 >>> False + 1 1 >>> True * 25 25 >>> False * 25 0
Class bool () or method () __ bool__ Returns the boolean value of an object [Python Documents]:
>>> bool(0)
False
>>> bool(1)
True
>>> bool("") # Empty String
False
>>> a = 15 >>> a.__bool__() True >>> a = -15 >>> a.__bool__() True >>> a = 0 >>> a.__bool__() False
In Python, lower objects are valued as Boolean False:
- None
- False
- Object zero (in various types): 0, 0.0, 0j
- All empty sequence objects: “”, (), []
- Empty dictionary object: {}
- Empty set object: () set
You will become familiar with unfamiliar things over time.
field
The “String” type in Python is created by placing a sequence of characters inside a pair of single “or double” quotation marks; Like ‘Python Strings’ or ‘Python Strings’ which are not different in type:
>>> a = "Python Strings" >>> a 'Python Strings' >>> print(a) Python Strings >>> import sys >>> sys.getsizeof(a) 63
Most of the time in interactive mode there is no need to use the print function (or command) but we should note that the interactive mode pays attention to the unambiguity of these outputs so it displays them in detail that is suitable for the programmer; For example, you must have noticed how the decimal and fraction types are displayed, or in the example of the code above, it can be seen that the string type is displayed with a quotation mark, or if the string text contains Escape characters, it sends them to the output without interpretation. . But print pays attention to the readability of its output and hides the details as much as possible; As a result, it displays cleaner text that is more suitable for the end user.
Unlike some languages, Python does not have a character type or char; In this language, a character is nothing but a string of length one.
In Python you can also use quotation marks inside each other; In this case, the internal quotation mark should only be different from the external one. If you want to use the same quote symbol, you must use the Escape characters, which will be examined below:
>>> "aaaaaa 'bbb'" "aaaaaa 'bbb'" >>> 'aaaaaa "bbb"' 'aaaaaa "bbb"' >>> "I'm cold!" "I'm cold!"
>>> 'I\'m cold!' "I'm cold!"
We are familiar with Docstring from the previous lesson; In another application, three quotation marks “” “or ” ‘are also used to create a string object. The advantage of this type of string is that the text can be simply written in a few lines with any desired indentation; It can be very useful when you want to use special code such as HTML in your application:
>>> a = """Python""" >>> a 'Python'
>>> html = """ ... <!DOCTYPE html> ... <html> ... <head> ... <title>Page Title</title> ... </head> ... <body> ... <h1>This is a Heading.</h1> ... <p>This is a paragraph.</p> ... </body> ... </html> ... """ >>> print(html) <!DOCTYPE html> <html> <head> <title>Page Title</title> </head> <body> <h1>This is a Heading.</h1> <p>This is a paragraph.</p> </body> </html> >>>
String as a Sequence
Some types of Python objects, such as string, tuple, list, etc., are also known as sequences. The sequence has properties that we will examine here with the help of the string type. The string is actually a sequence of characters so each member of this sequence can be accessed using its position index; The member index starts at zero on the left and increases one unit to the right. For example, for the ‘Python Strings’ object, we can consider the indexing schema below:
P y t h o n S t r i n g s - - - - - - - - - - - - - - 0 1 2 3 4 5 6 7 ... 13
To obtain the members of a sequence named seq from the pattern seq [i], i of which is the index of the member in question; Used:
>>> a = "Python Strings" >>> a[0] 'P' >>> a[7] 'S' >>> a[6] ' '
some notes:
The seq [-i] pattern scrolls the sequence members from the right; The index to the right of the member is -1 and decreases to the left of one unit by one, respectively.- The pattern seq [i: j] achieves the members of the sequence that are in the range from index i to before index j. To express the points “from the beginning” and “to the end” can not be mentioned i and j, respectively.
- The pattern seq [i]: j: k is the same as before, except that k determines the step size of the members.
- Using the len () function, the number of members of a sequence can be obtained [Python documents].
>>> a = "Python Strings" >>> len(a) 14 >>> a[-2] 'g' >>> a[2:4] 'th' >>> a[7:] 'Strings' >>> a[:6] 'Python' >>> a[:-1] 'Python String' >>> a[2:12:3] 'tntn' >>> a[:6:2] 'Pto' >>> a[7::4] 'Sn' >>> a[-1] 's' >>> a[len(a)-1] 's'
It should be noted that a string object is an immutable type of Python and its value (or sequence members) cannot be changed; For example, the ‘Python Strings’ object cannot be changed to ‘Python-Strings’ – all you have to do is create a new object:
>>> a = "Python Strings" >>> a[6] = "-" Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
Operators for strings
Strings can also use the + (to link strings) and * (to repeat strings) operators:
>>> a = "Python" + " " + "Strings" >>> a 'Python Strings' >>> "-+-" * 5 '-+--+--+--+--+-'
You can skip the + operator to link and link them only by stringing them together; Of course, this method is not correct when you use a variable:
>>> "Python " "Programming " "Language" 'Python Programming Language'
>>> a, b, c = "Python ", "Programming ", "Language" >>> a + b + c 'Python Programming Language'
To check the equality of the values of two strings like other objects, the == operator can be used:
>>> a = "py" >>> b = "PY" # Uppercase >>> a == b False
Membership operators can also be used to check for characters or strings within other strings:
>>> "n" in "python" True >>> "py" not in "python" False
You will see a little later that the% operator is also used to format strings.
Escape characters
By default, a certain number of characters are defined that can be used within strings. All of these characters start with a \, which is why they are sometimes called Backslash Characters. In fact, these characters are a possibility to insert some other characters that can not be easily entered by the keyboard. For example, one of the common Escape characters is n \, which represents a character with ASCII code 10 (LF) called newline; n \ Wherever the string (or text) is inserted ends the current line when printed and the continuation of the string (or text) begins with the new line [Python Documents]:
>>> a = "Python\nProgramming\nLanguage" >>> a 'Python\nProgramming\nLanguage' >>> print(a) Python Programming Language >>>
Some of these characters are as follows:
- n \ – End the current line and go to the new line
- t \ – Equivalent to Ski Code 9 (TAB): Insert eight spaces (Space key)
- uxxxx \ – Insert a 16-bit Unicode character using its hexadecimal value (base sixteen): “u067E \”
- Uxxxxxxxx \ – Insert a 32-bit Unicode character using its hexadecimal value (base 16): “U0001D11E \”
- ooo \ – Insert a character using its octal value (base eight): “123 \”
- xhh \ – Insert a character using its hexadecimal value (base sixteen): “x53 \”
- ‘\ – Insert a character’
- “\ – Insert a character”
- \\ – Insert a character \
This feature of strings sometimes causes problems; Suppose we want to print the file address of a Windows operating system:
>>> fpath = "C:\new\text\sample.txt" >>> print(fpath) C: ew ext\sample.txt
To solve the sample code problem above, you can use \\ wherever needed: “C: \\ new \\ text \\ sample.txt”. But the more comprehensive solution is to create “raw strings”; In this type of string, Escape characters are ineffective. The raw string is created by adding a letter r or R to the beginning of a regular string:
>>> fpath = r"C:\new\text\sample.txt" >>> print(fpath) C:\new\text\sample.txt
Convert code to characters and vice versa
We know that in order for a computer to understand characters, it needs systems that encode them to become base code two; Such as the ASCII system or more comprehensive systems such as UTF-8, which is available under the Unicode standard. Sometimes we need to access these codes and work with the characters based on them; For this purpose, in Python, you can use two functions: ord () (converting code to character) [Python documents] and () chr (converting character to code) [Python documents]. The ord () function takes a single-character string and returns a number (in base ten) that represents the character code in question. The chr () function also takes the character code (which must be a number in base ten) and returns the corresponding character:
>>> # Python 3.x - GNU/Linux
>>> ord("A")
65
>>> chr(65)
'A'
>>> int("067E", 16) # Hexadecimal to Decimal
1662
>>> chr(1662) # Unicode Character: 1662 -> 067E -> 'پ'
'پ'
>>> ord(_) # _ is result of the last executed
statement = 'پ'
1662
>>> ord("\U0001D11E")
119070
>>> chr(_)
'𝄞'
Because 2x versions of Python do not support Unicode-standard encoding by default; To get the Unicode character (characters outside the ASKI range) from its code, we need to use a separate function called unichr (Python Documents):
>>> # Python 2.x - GNU/Linux
>>> ord("a")
97
>>> chr(97)
'a'
>>> unichr(1662)
u'\u067e'
>>> print _
پ
>>> ord(u"\U0001D11E")
119070
>>> unichr(_)
u'\U0001d11e'
>>> print _
𝄞
Convert to string type
To convert objects of another type to a string type; There is a str () [Python Documents] class and a repr (Python Documents) function (). The str () class returns an informal instance of the string object type; Informal in that it obscures the details of the string object. But the repr () function returns an official instance of the Python string type. Earlier, we talked about the difference between print output and interactive mode; In fact, the output (str) is suitable for printing and, like print, does not provide the details of this type of object, while repr (), like interactive mode, returns a complete representation of the string object:
>>> str(14) '14' >>> repr(14) '14' >>> str(True) 'True' >>> repr(False) 'False'
>>> a = "Python Strings" >>> str(a) 'Python Strings' >>> repr(a) "'Python Strings'" >>> print(str(a)) Python Strings >>> print(repr(a)) 'Python Strings'
You can also use the __ str__ () and __ repr__ () methods instead of these two:
>>> a = 10 >>> a.__str__() '10'
String Formatting
Formatting is the ability to replace one or more values (in other words, an object) – sometimes with arbitrary modifications – within a string that is implemented in Python in two ways [Python Documents]:
1. Traditional format – with pattern (s … “% (values% …”
It consists of two parts; The left-hand side of the% operator specifies a string that contains one or more object placement codes – the placement codes all start with a% character; Such as: s% – and to the right of it are parentheses to replace in the string; These objects are placed in sequence from the left:
>>> "Python is %s to learn if you know %s to start!" %
("easy", "where")
'Python is easy to learn if you know where to start!'
Some of the placement codes are as follows:
- s% – Replace in the form of a string in the output of class () str
- r% – Replace in the form of a string with the output of the function () repr
- c% – Substitution in the form of a character: Converts an integer that represents the character code to a Unicode character and places it inside the string.
>>> "%r is a %s language." % ("Python", "programming")
"'Python' is a programming language."
>>> er = 1427
>>> "Error %s!" % (er)
'Error 1427!'
>>> "A, B, C, ... Y, %c" % (90)
'A, B, C, ... Y, Z'
- d% or i% – Substitute in the form of an integer in base ten
- o% – Substitute in the form of an integer in base eight
- x% – Substitute in the form of an integer in base sixteen in lower case
- X% – Substitute in the form of an integer in base sixteen in capital letters
>>> "4 + 4 == %d" % (2*4)
'4 + 4 == 8'
>>> "%d" % (0b0110)
'6'
>>> "%d" % (12.6)
'12'
>>> "int('%o', 8) == %d" % (0o156, 0o156)
"int('156', 8) == 110"
>>> "15 == %X in HEX" % (15)
'15 == F in HEX'
- f% – Substitution in the form of a floating point number (default accuracy: 6) in base ten
- F% – same as f%; With the difference that it inserts nan and inf as NAN and INF.
- e% – Substitution in the form of a floating point number in the form of a scientific symbol with a lowercase letter
- E% – Substitution in the form of a floating point number in the form of a scientific symbol with a capital letter
>>> "%f" % (12.526) '12.526000' >>> "%f" % (122e-3) '0.122000' >>> "%E" % (12.526) '1.252600E+01'
This template can also be implemented using a dictionary object this type of object is examined in the second part of the Object Types lesson. In this way, objects are placed using the key and their order no longer matters. Note the example code below:
>>> '%(qty)d more %(product)s' % {'product': 'book', 'qty': 1}
'1 more book'
>>> reply = """
... Greetings...
... Hello %(name)s!
... Your age is %(age)s
... """
>>> values = {'name': 'Bob', 'age': 40}
>>> print(reply % values)
Greetings...
Hello Bob!
Your age is 40
>>>
In principle, for the left part of this template, a structure such as the following can be considered:
%[(keyname)][flags][width][.precision]typecode
- In each use, the existence of each [] is optional or depends on the use.
- (keyname) – Insert the key in parentheses – when using a dictionary object.
- flags – can be one of the three symbols +, – and 0. + Causes the number sign to be inserted (the negative number sign is inserted by default; this symbol is mostly used to insert the positive number sign), – causes the value to be left over (the default mode is correct) and 0 determines that the extra empty space with Fill to zero (Space is set by default).
- width – Specifies the string size; In cases where the specified size is greater than the actual value of the value, the extra space can be filled with zero or empty space, and of course, when it is less specified, this option is ignored.
- precision. – In the case of floating point numbers, determines the accuracy or number of digits after the point (default accuracy: 6). In cases where the specified number is less than the actual number of digits after the discriminant, the number is rounded. To exist. Pay attention before that.
- typecode – represents the same letter that determines the type of placement code.
- Instead of width and precision. * Can be used, in which case the number corresponding to them is also given in the right part, and the replacement object must be mentioned right after it. This option is used when it is necessary to determine these numbers during the execution of the program.
>>> "%6d" % (256) # typecode='d' width='6' ' 256' >>> "%-6d" % (256) # typecode='d' width='6' flags='-' '256 ' >>> "%06d" % (256) # typecode='d' width='6' flags='0' '000256' >>> "%+d" % (256) # typecode='d' flags='+' '+256'
>>> "%10f" % (3.141592653589793) # typecode='f' width='10' ' 3.141593' >>> "%10.4f" % (3.141592653589793) # typecode='f' precision='4' width='10' ' 3.1416' >>> "%10.8f" % (3.141592653589793) # typecode='f' precision='8' width='10' '3.14159265' >>> "%-10.0f" % (3.141592653589793) # typecode='f' precision='0' width='10' flags='-' '3 '
>>> "%*d" % (5, 32)
# typecode='d' width='5'
' 32'
>>> "%d %*d %d" % (1, 8, 8231, 3)
'1 8231 3'
>>> "%f, %.2f, %.*f" % (1/3.0, 1/3.0, 4, 1/3.0)
'0.333333, 0.33, 0.3333'
>>> n = """
... %15s : %-10s
... %15s : %-10s
... """
>>> v = ("First name", "Richard", "Last name", "Stallman")
>>> print(n % v)
First name : Richard
Last name : Stallman
>>>
2. New format, call method () format – with template format (values). “… {} …”
Available in Python versions 2.6, 2.7 and 3x; Objects are arguments to a specified method and are placed in {} using the position index or their names:
>>> '{0} {1} {2}'.format("Python", "Programming", "Language")
'Python Programming Language'
>>> reply = """
... Greetings...
... Hello {name}!
... Your age is {age}
... """
>>> print(reply.format(age=40, name='Bob'))
Greetings...
Hello Bob!
Your age is 40
>>>
>>> "{0} version {v}".format("Python", v="3.4")
'Python version 3.4'
consideration
As we will learn in the function lesson; Arguments can be sent to them by assigning the desired value without the need to follow the order.
Objects can be placed in any order:
>>> '{2}, {1}, {0}'.format('a', 'b', 'c')
'c, b, a'
From version 2.7 onwards, if we want the objects to be placed in the order in which they are in the method argument; There is no need to mention the index or the name of the argument:
>>> '{}, {}, {}'.format('a', 'b', 'c') # 2.7+ only
'a, b, c'
Its members can be accessed by bringing an * behind an argument that is a sequence object. Of course, if we want to use other arguments, they need to be at the beginning of the method, in which case the index count starts from them; Note the example code below:
>>> '{2}, {1}, {0}'.format(*'abc')
'c, b, a'
>>> '{2}, {1}, {0}'.format(*'python')
't, y, p'
>>> '{2}, {1}, {0}'.format('z', *'abc')
'b, a, z'
The intra-string section of this template has a similar structure below:
{fieldname !conversionflag :formatspec}
- fieldname – is the index or name of the argument.
- conversionflag! – can be one of the letters r and s that call repr () and str () on the object, respectively. Note that these letters with! They start:
>>> "repr() shows quotes: {!r}; str() doesn't: {!s}".format
('test1', 'test2')
"repr() shows quotes: 'test1'; str() doesn't: test2"
- formatspec: – Determines how to insert an object in the string. It starts with: and has a structure like the one below:
[[fill]align][sign][#][0][width][,][.precision][typecode]
- In each use, the existence of each [] is optional or depends on the use.
- fill – can be any printable character – This option is used to fill in the space created by width.
- align – can be one of the characters <,> or , which represent the right, left and middle characters, respectively. width is also given after them, which determines the size of the string.
>>> '{0:<30}'.format('left aligned')
# align='<' width='30'
'left aligned '
>>> '{0:>30}'.format('right aligned')
# align='>' width='30'
' right aligned'
>>> '{0:^30}'.format('centered')
# align='^' width='30'
' centered '
>>> '{0:*^30}'.format('centered')
# align='^' width='30' fill='*'
'***********centered***********'
- sign – is used to display the number sign and can be one of the symbols +, – or a space. In this way: + inserts the sign of all positive and negative numbers and – also causes only the insertion of the negative numbers. If empty space is used, a negative number symbol is inserted, but instead of a positive number symbol, a blank space character is entered.
>>> '{0:+f}; {1:+f}'.format(3.14, -3.14)
# typecode='f' sign='+'
'+3.140000; -3.140000'
>>> '{0:-f}; {1:-f}'.format(3.14, -3.14)
# typecode='f' sign='-'
'3.140000; -3.140000'
>>> '{0: f}; {1: f}'.format(3.14, -3.14)
# typecode='f' sign=' '
' 3.140000; -3.140000'
- Unlike the traditional format, we can also have a base two conversion. Base conversion in this format is done using the letters b (base two), o (lowercase letter – base eight) and x or X (base sixteen). If a # symbol is added before them, the base prefix is also inserted:
>>> "int: {0:d}; hex: {0:x}; oct: {0:o};
bin: {0:b}".format(42)
'int: 42; hex: 2a; oct: 52; bin: 101010'
>>> "int: {0:d}; hex: {0:#x}; oct: {0:#o};
bin: {0:#b}".format(42)
'int: 42; hex: 0x2a; oct: 0o52; bin: 0b101010'
- Using a coma, a number can be separated by three digits from the right:
>>> '{0:,}'.format(1234567890)
'1,234,567,890'
- Parts of the traditional template are also defined in this template. Precision options, typecode. And width are the same as in the traditional format. Of course, typecode cases are a bit less; For example, in this format there is no code i and only d can be used for integers in base ten:
>>> '{0:06.2f}'.format(3.14159)
# width='6' precision='.2' typecode='f' and [0]
'003.14'
>>> '{0:^8.2f}'.format(3.14159) # align='^'
' 3.14 '
- To express a percentage,% can be used instead of f:
>>> points = 19.5
>>> total = 22
>>> 'Correct answers: {0:.2%}'.format(points/total)
'Correct answers: 88.64%'
- In the traditional format, we could set our options on the other side using *; In the new format, we can use for this purpose, like we did to place objects, and define the value of the options in the position of the method argument:
>>> text = "Right"
>>> align = ">"
>>> '{0:{fill}{align}16}'.format(text, fill=align, align=align)
'>>>>>>>>>>>Right'
f-string
Python 3.6 introduces a new and very interesting possibility in string formatting, known as f-string [PEP 498].
The structure is the same as the simplified (str.format) mode:
>>> name = "Saeid"
>>> age = 32
>>> f"Hello, {name}. You are {age}."
'Hello, Saeid. You are 32.'
>>>
That is, if we put the letter f or F at the beginning of a text, then we can put our variables or expressions directly inside it using -{}:
>>> f"{2 * 37}"
'74'
Obviously, variables (- or the result of expressions) or objects used in the f-string method must eventually be converted to string type to fit within the text or string. In this method, __ str__ () method is called to convert to string type by default, but can be done by placing the r! At the end of the object, specify that the __ repr__ () method be called:
>>> name = 'Saeid'
>>> print(f'My name is {name}')
My name is Saeid
>>> print(f'My name is {name!r}')
My name is 'Saeid'
>>>
In this method, the symbol {} can be used outside the formatting principles, but it should be noted that both symbols {{}. Are considered as a {.. The existence of three {{{}}} is also in the sentence of the same two:
>>> f'{{{{32}}}}'
'{{32}}'
>>> f'{{{32}}}'
'{32}'
>>> f'{{32}}'
'{32}'
>>> f'{32}'
'32'
>>> print(f'{{My name}} is {name}')
{My name} is Saeid
>>> print(f'{{My name}} is {{name}}') # NOTE!
{My name} is {name}
>>> print(f'{{My name}} is {{{name}}}')
{My name} is {Saeid}
>>> print(f'{{My name}} is {{{{name}}}}') # NOTE!
{My name} is {{name}}
In the example code below, we call a function directly inside the existing text:
>>> def to_lowercase(input):
... return input.lower()
...
>>>
>>> name = "Eric Idle"
>>>
>>> f"{to_lowercase(name)} is funny."
'eric idle is funny.'
>>> f"{name.lower()} is funny."
'eric idle is funny.'
>>>
We can also format each of the objects used in the text in the specific way of that object, by placing one: separately:
>>> a_float_number = 5.236501
>>> print(f'{a_float_number:.4f}')
5.2365
>>> print(f'{a_float_number:.2f}')
5.24
>>>
>>> a_int_number = 16
>>> print(f'{a_int_number:05d}')
00016
>>>
>>> import datetime
>>> now = datetime.datetime.now()
>>> print(f'{now:%Y-%m-%d %H:%M}')
2019-10-20 10:37
In future lessons we will talk about the datetime module. [Python Documents]
Some functional methods of a string object
- Capitalize () Python documents – Returns a copy of a string whose first letter is capitalized (Capital):
>>> a = "python string methods" >>> a.capitalize() 'Python string methods'
- center (width) [Python documents] – takes an integer that specifies the size of the string and returns the string in the middle of this interval if the specified size is less than the actual size of the string (len (string)); The string is returned unchanged.This method also has an optional argument by which a character can be specified to fill in the blank:
>>> a = "python" >>> a.center(25) ' python ' >>> a.center(25, "-") '----------python---------'
There are two other similar methods with the template rjust (width) [Python documents] and ljust (width) [Python documents] that are used to straighten and string text, respectively:
>>> a.rjust(25) ' python' >>> a.ljust(25, ".") 'python...................'
- count (sub) [Python documents] – takes a string and returns the number of occurrences in the main string. This method also has two optional arguments start [, end,]]] that can be used to specify the start and end point of this method :
>>> a = "python string methods"
>>> a.count("t")
3
>>> a.count("tho")
2
>>> a.count("tho", 15) # start=15
1
>>> a.count("tho", 0, len(a)-1)
# start=0 end=20 -> len(a)==21 : 0 ... 20
2
- endswith (suffix) [Python Documents] – takes a string and returns the value True and otherwise False if the main string ends with it. This method also has two optional arguments start [, end,]]] that can be Specify the start and end point of this method:
>>> a = "Wikipedia, the free encyclopedia."
>>> a.endswith(",")
False
>>> a.endswith(",", 0 , 10) # start=0 end=10
True
>>> a.endswith("pedia.", 14) # start=14
True
- find (sub) [Python Documents] – takes a string and returns its start index for the first occurrence within the main string; if the received argument is not found in the main string, the value is returned 1. This method also has two optional arguments start [, end,]]] where the start and end point of this method can be specified:
>>> a = "python programming language"
>>> a.find("language")
19
>>> a.find("p")
0
>>> a.find("p", 6) # start=6
7
>>> a.find("g", 18, len(a)-1) # start=18 end=27-1
22
>>> a.find("saeid")
-1
There is another similar method with the template rfind (sub) [Python documents], except that the index returns the received argument for the last occurrence within the main string:
>>> a.rfind("p")
7
>>> a.rfind("p", 6)
7
>>> a.rfind("g", 18, len(a)-1)
25
>>> a.rfind("saeid")
-1
If you do not need an index and only want to check the existence of a string within a specific string; Use the in operator:
>>> "language" in a True >>> "p" in a True >>> "saeid" in a False
- index (sub) [Python documents] – is the same as the method find (sub) except that if the received argument is not found in the main string, it reports a ValueError error:
>>> a = "python programming language"
>>> a.index("python")
0
>>> a.index("python", 6)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
There is another method with the template rindex (sub) [Python documents] that works like rfind (sub) but reports a ValueError error if the received argument is not found in the main string:
>>> a.rindex("g", 18, len(a)-1)
25
- join (iterable) [Python Documents] – Receives a sequence with whole members of the string type as an argument and connects and returns its members using the main string:
>>> a = "-*-"
>>> a.join("python")
'p-*-y-*-t-*-h-*-o-*-n'
>>> a.join(['p', 'y', 't', 'h', 'o', 'n'])
# get a list of strings
'p-*-y-*-t-*-h-*-o-*-n'
- split (sep) [Python Documents] – Receives a character and separates the string according to it and returns it as a list object. This method also has an optional argument that can be used to specify the number of separation operations. Appearance:
>>> a = "p-y-t-h-o-n"
>>> a.split()
['p-y-t-h-o-n']
>>> a.split("-")
['p', 'y', 't', 'h', 'o', 'n']
>>> a.split("-", 2)
['p', 'y', 't-h-o-n']
>>> '1,2,,3,'.split(',')
['1', '2', '', '3', '']
There is another similar method with the template rsplit (sep) [Python documents] but with the difference that it scrolls the string from the right:
>>> a.rsplit("-")
['p', 'y', 't', 'h', 'o', 'n']
>>> a.rsplit("-", 2)
['p-y-t-h', 'o', 'n']
- replace (old, new) [Python Documents] – Receives two strings as arguments; in all major strings, replaces the parts that are equal to the value of the old argument with the new argument and then returns the new string. This method also has an optional argument. Which can determine the number of replacement operations:
>>> a = "He has a blue house and a blue car!"
>>> a.replace("blue", "red")
'He has a red house and a red car!'
>>> a.replace("blue", "red", 1)
'He has a red house and a blue car!'
- () lower [Python Documents] – Converts all English letters in the string to lowercase and returns:
>>> "CPython-3.4".lower() 'cpython-3.4'
upside down; The upper () method [Python Documents] converts all English letters in the string to uppercase and returns:
>>> "CPython-3.4".upper() 'CPYTHON-3.4'
- islower () (Python Documents) – Returns the value True and otherwise False if the string contains at least one letter of the English alphabet and all the letters of the alphabet are lowercase:
>>> "python".islower() True >>> "python-3.4".islower() True >>> "Python".islower() False
upside down; Isupper () method [Python Documents] Returns the value True and otherwise False if the string contains at least one letter of the English alphabet and all the letters of the alphabet are uppercase:
>>> "python".isupper() False >>> "Python".isupper() False >>> "PYTHON".isupper() True >>> "PYTHON-3.4".isupper() True
- isalpha () (Python Documents) – Returns the value True and otherwise False if the string contains at least one character and all its characters are just one of the letters of the English alphabet (lowercase or uppercase):
>>> "python".isalpha() True >>> "python34".isalpha() False >>> "python 34".isalpha() False
- () isalnum [Python Documents] – Returns the value True and otherwise False if the string contains at least one character and all its characters are just one of the numbers 0 to 9 or the English alphabet (lowercase or uppercase):
>>> "python34".isalnum() True >>> "python3.4".isalnum() False >>> "python-34".isalnum() False
- isdigit () [Python Documents] – Returns the value True and otherwise False if the string contains at least one character and all its characters are just one of the numbers 0 to 9:
>>> "python34".isdigit() False >>> "34".isdigit() True >>> "3.4".isdigit() False
Types of strings
How to present the string type is a major difference in the 2x and 3x versions of Python.
In 2x versions, a comprehensive type of str that is limited to ASCII encoding; It includes both regular string and binary data formats (encoded texts, media files, and network messages) – the binary string is denoted by a letter b at the beginning. In this series of versions there is another type called unicode, which includes strings outside the scope of ASCII coding; To create this type of object, the string must start with a letter u:
>>> # python 2.x >>> a = "python" >>> type(a) <type 'str'> >>> a = b"python" >>> type(a) <type 'str'> >>> a = u"python" >>> type(a) <type 'unicode'>
In addition to placing the letter u at the beginning of the string to create a Unicode string, the unicode () function can also be used by specifying the coding system:
>>> # python 2.x
>>> u = unicode("python", "utf-8")
>>> type(u)
<type 'unicode'>
>>> u
u'python'
>>> print u
python
>>> fa = u"پ"
>>> fa
u'\u067e'
>>> print fa
پ
So the types of strings in Python 2x:
- Typical strings (limited to ASCII coding) + binary data: str
- Unicode strings: unicode
But in 3x versions, the string is offered by three types. The default character encoding in Python is now much broader than ASCII and supports the Unicode standard, so the str type alone can contain almost all the characters in the world, and there is no need to use a separate type and the letter u to specify Unicode strings; Therefore, in these versions, only one type of str is provided for all ski disciplines and Unicode. Another change has occurred that the binary data type is separated from the regular strings and is represented by a new type called bytes:
>>> # Python 3.x >>> a = "python" >>> type(a) <class 'str'> >>> a = b"python" >>> type(a) <class 'bytes'> >>> a = u"python" >>> type(a) <class 'str'>
So the types of strings in Python 3x:
- Common strings (ASCII and Unicode): str
- Binary data: bytes
- Mutable type for binary data: bytearray – This type is actually a variable byte sequence that is also available in versions 2.6 and 2.7.
In Python 3x, to create the type of bytes, in addition to the letter b, the bytes () class can also be used [Python documents]. In the argument of this class for the type of string, it is necessary to specify its coding system; It is also better to send numerical data in the form of a list object:
>>> # Python 3.x
>>> b = b"python" >>> b b'python'
>>> b = bytes("python", "utf-8")
>>> b
b'python'
>>> c = bytes([97])
>>> c
b'a'
Now we need to decode the data to convert the bytes type to str; This can be done using the decode () method or the str () class by specifying the decoding system:
>>> type(b)
<class 'bytes'>
>>> print(b)
b'python'
>>> b.decode("utf-8")
'python'
>>> str(b, "utf-8")
'python'
Like the bytes class (), this time the bytearray () class is used to create the bytearray type:
>>> # Python 3.x
>>> b = bytearray("python", "utf-8")
>>> b
bytearray(b'python')
>>> print(b)
bytearray(b'python')
>>> b[0]
112
>>> b[0] = 106 # 106='j'
>>> b.decode("utf-8")
'jython'
>>> str(b, "utf-8")
'jython'
😊 I hope it was useful
Use the online HTML beautifier website to easily edit and convert the markup code for web pages!